Basic Machine Learning Concepts#
This MD file is to test the LaTeX display
Overfitting / Underfitting
Overfitting refers to a model that matches the training data too closely, including its noise and outliers, which diminishes the model’s ability to generalize to new data. This results in excellent performance on the training set but poor performance on validation/test sets.
Solutions to overfitting generally include:
- Reducing the number of features appropriately.
- Adding a regularization term. Regularization aims to reduce the influence of features on the prediction outcome. Common regularization terms include L1 and L2 regularization.
Underfitting is the opposite, where the model lacks sufficient complexity to capture the underlying patterns in the data.
Solutions to underfitting include:
- Increasing the number of training epochs.
- Adding more features to the model.
- Reducing the regularization term.
Bias / Variance Trade-off
Bias refers to the difference between the model’s predicted values and the actual values, describing the model’s fitting ability.
Variance describes the model’s sensitivity to different datasets, indicating how much the data fluctuations affect the model.
Generally, simpler models have higher bias and lower variance, while more complex models have lower bias and higher variance. This also corresponds to the concepts of overfitting and underfitting.
A common method to balance bias and variance is cross-validation. The basic method of k-fold cross-validation is to divide the training set into k parts. Each time, one part is used as the validation set, and the remaining k-1 parts are used as the training set. This process is repeated k times, ensuring that each part is used as the validation set. The final loss is the average of the k training losses.
Regularization#
L1 vs. L2 Regularization
L1 Regularization, also known as LASSO, is the sum of the absolute values of all parameters.
L2 Regularization, also known as Ridge, is the square root of the sum of the squares of all parameters.
Both types of norms help reduce the risk of overfitting. L1 norm can be used for feature selection, but it cannot be directly differentiated, so conventional gradient descent/Newton’s method cannot be used for optimization. Common methods include coordinate descent and Lasso regression. L2 norm is easier to differentiate.
Sparsity of L1 Norm / Why L1 Regularization Can Be Used for Feature Selection
Compared to L2 norm, L1 norm is more likely to yield sparse solutions, meaning it can optimize unimportant feature parameters to 0.
Understanding this:
Suppose the loss function has a certain relationship with a parameter as shown below. The optimal point is at the red dot where .
- Adding L2 regularization results in a new loss function , where the optimal is at the blue dot, reducing ’s absolute value but still non-zero.
- Adding L1 regularization results in a new loss function , making the optimal equal to 0.
When L2 regularization is added, the loss function’s minimum at occurs only when the original loss function’s derivative is zero. With L1 regularization, becomes a minimum point if the parameter and the loss function’s derivative satisfy .
L1 regularization leads to many parameters becoming zero, making the model sparse, which can help in feature selection.
Evaluation Metrics in Machine Learning#
- Precision / Recall / F1 Score
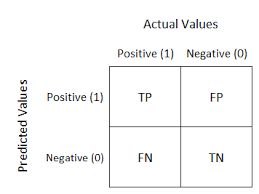
For binary classification problems, precision, recall, and F1 score are often used to evaluate the model’s performance. The prediction results can be divided into:
- TP (True Positive): Correctly predicted positive class.
- TN (True Negative): Correctly predicted negative class.
- FP (False Positive): Incorrectly predicted positive class.
- FN (False Negative): Incorrectly predicted negative class.
Definitions:
Precision: The ratio of correctly predicted positive observations to the total predicted positives.
Recall: The ratio of correctly predicted positive observations to all observations in the actual class.
F1 Score: The harmonic mean of precision and recall.
- Confusion Matrix
The confusion matrix for classification results is shown below:
- Macro-F1 vs. Micro-F1
When there are multiple binary classification confusion matrices (e.g., multiple training and testing datasets/multiple datasets/pairwise combinations in multi-class tasks), we want to evaluate the model performance comprehensively across n binary classification confusion matrices.
Macro-F1: Directly calculate the precision and recall for each confusion matrix, then average them to get macro-P, macro-R, and the corresponding macro-F1.
Micro-F1
Another approach is to first average the corresponding elements of each confusion matrix to obtain , , , and . Then, based on these values, calculate micro-, micro-, and the corresponding micro-.
- ROC Curve / AUC Area
ROC Curve (Receiver Operating Characteristic) and AUC (Area Under ROC Curve) are the most commonly used evaluation metrics for imbalanced classification problems. To understand what ROC is, we first define two metrics based on the confusion matrix: True Positive Rate (TPR) and False Positive Rate (FPR).
Ideally, a good model should satisfy high TPR and low FPR. For any trained model, we can calculate its TPR and FPR on the given test data. By plotting FPR on the x-axis and TPR on the y-axis, we can represent any model’s (FPR, TPR) pair in this coordinate system, as shown in the figure below. The space constructed by this coordinate system is called the ROC space. In the example, there are five models: A, B, C, D, and E. In the ROC space, the closer a model is to the top left corner, the better it is.
In most binary classification problems (especially in neural networks), the decision to classify a sample as positive or negative is based on setting a threshold. If the value exceeds this threshold, the sample is labeled as positive; otherwise, it is labeled as negative. Usually, this threshold is set to 0.5. If we try different thresholds to separate positive and negative classes, we can obtain multiple (FPR, TPR) pairs. By plotting these pairs, we can draw a curve in the ROC space, known as the ROC Curve. If the (FPR, TPR) points are sufficiently dense, we can calculate the area under the curve, known as the AUC Area.
Loss and Optimization#
- Convex Optimization Problems
An optimization problem is a convex optimization problem if its objective function is a convex function and the feasible region is a convex set (a set where any line segment between two points in the set lies entirely within the set).
A function defined on a convex domain is convex if and only if for any and , we have:
The importance of convex optimization problems in mathematics lies in the fact that the local optimum of a convex optimization problem is also its global optimum. This property allows us to use greedy algorithms, gradient descent methods, Newton’s methods, etc., to solve convex optimization problems. In fact, many non-convex optimization problems are solved by breaking them down into several convex optimization problems and solving them individually.
- MSE / MSELoss
Mean Square Error (MSE) is the most common metric in regression tasks.
- Is Logistic Regression with MSELoss a Convex Optimization Problem?
No. Logistic regression maps a linear model to a classification problem through the sigmoid nonlinear function. Its MSE is a non-convex function, and the optimization process might result in a local optimum instead of a global optimum. Therefore, logistic regression with MSELoss is not a convex optimization problem.
- Relationship Between Linear Regression, Least Squares Method, and Maximum Likelihood Estimation
The common methods for solving linear regression are the Ordinary Least Squares (OLS) method and the Maximum Likelihood Estimation (MLE) method.
The least squares method uses the sum of the squared differences between predicted and actual values as the loss function (MSELoss).
Maximum likelihood estimation estimates the model parameters by maximizing the likelihood of the observed data. Given and , it estimates the most likely model parameters. Assuming the error follows a Gaussian distribution, the probability density function is:
Substituting , we get:
The likelihood function is: